
Este será um guia, até mesmo para o meu ’eu do futuro’, mostrando, passo a passo, como montar um sistema de visualização de mídias. O objetivo principal é ter uma maneira de assistir quaisquer filmes e séries a partir de qualquer lugar, sem depender de serviços de streaming com tipos limitados de filmes, e que, além de removerem algumas mídias da plataforma que já estavam disponíveis, podem colocar anúncios mesmo no plano pago e não receber qualidade 4k ainda que se pague por isso.
A ideia é que ao final deste blog post, você consiga ter um norte para montar um sistema de requisição e visualização de mídias automatizado. Ao apertar um botão para requisitar um filme, o sistema irá baixá-lo com a melhor qualidade possível, com legendas já pré-configuradas e disponíveis para assistir em qualquer dispositivo.
Mas já adianto que não é simples, é preciso entender como cada parte funciona e integra com tudo. Cada serviço tem suas particularidades e para usar da melhor forma você terá que gastar umas horas lendo documentação e vendo vídeos no YouTube. Eu demorei mais de uma semana pra deixar tudo funcional e ainda tem muitas coisas a melhorar.
Apesar de ser um guia introdutório, ainda será um guia técnico, pois iremos usar vários programas que irão se comunicar entre si. Então, é esperado que se tenha ao menos um conhecimento prévio de alguns assuntos como docker, servidores, redes, vídeos, etc.
TL;DR: Como configurar os serviços Jellyfin, Jellysseer, Bazarr, Radarr, Sonarr, Prowlarr, qBitTorrent e outros.
Hardware
Para hospedar os serviços, precisamos de um hardware. Neste caso, pode ser desde um notebook velho que esteja parado até um próprio servidor alocado. No meu caso, eu uso um NanoPi R4S de 4Gb de RAM para rodar tudo, mas o mais importante aqui é que tenha um pouco de armazenamento pra guardar os filmes/séries.

A ideia é que possa ser algo que irá servir como um servidor, ou seja, que fique rodando 24/7 na tomada, para poder acessar os serviços a qualquer momento.
Serviços
Atualmente, a maneira mais prática de rodar os programas é via containers, mais precisamente utilizando docker com docker compose. Particularmente, crio uma pasta para tudo que eu hospedo na minha casa, assim, a árvore de diretórios fica desta forma:
.
├── appdata
│ └── ...
├── configs
│ └── ...
├── docker-compose.yaml
└── README.md
O arquivo docker-compose.yaml contém todos os containeres necessários para rodar os serviços. As pastas configs e appdata contém, respectivamente, os arquivos de configuração e arquivos de dados das aplicações (que não são úteis a ponto de merecerem ser salvos no git, por exemplo).
Iremos utilizar os programas Jellyfin, Jellyseerr, Bazarr, Prowlarr, Radarr e Sonarr.
Funciona mais ou menos assim:
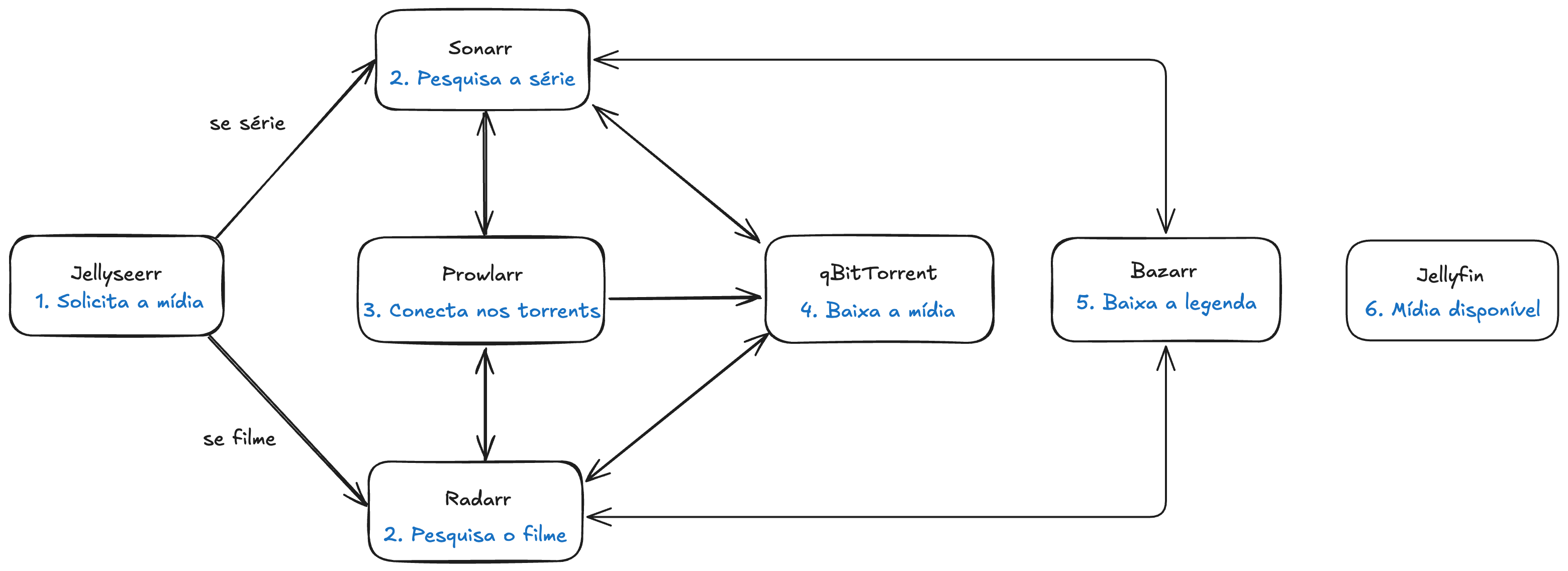 A única parte manual é o passo 1, o resto irá rodar tudo em background. Jellyfin é onde iremos assistir as mídias e por ele ler os arquivos do HD/SSD, ele não se conecta com os outros programas, pois as mídias já estarão prontas no HD.
A única parte manual é o passo 1, o resto irá rodar tudo em background. Jellyfin é onde iremos assistir as mídias e por ele ler os arquivos do HD/SSD, ele não se conecta com os outros programas, pois as mídias já estarão prontas no HD.
Estrutura de arquivos
Uma das coisas que não vejo muitos falando é sobre como melhor estruturar os diretórios e arquivos das mídias. Não queremos arquivos duplicados, pois filmes podem ocupar muito espaço.
O ideal nesta parte é ter um HD/SSD apenas para conter as mídias. Assim, é possível reusá-lo em qualquer outro dispositivo. Por usar docker, é recomendado estruturar os volumes dos containers de forma adequada para que múltiplas cópias possam existir ocupando espaço apenas uma vez, os chamados hardlinks. A convenção da comunidade é estruturar assim:
/mnt/gigachad/data
├── media
│ ├── movies
│ └── tv
└── torrents
├── movies
└── tv
É importante que os diretórios e volumes dos containers sejam consistentes, para que os hardlinks funcionem corretamente. Recomendo ler o TRaSH Guides, tem muita informação útil sobre isso.
Para começar, crie o arquivo docker-compose.yaml e siga as instruções de cada serviço a seguir. Uma vez completo, execute docker compose up -d.
qBitTorrent
Este é o programa principal que irá baixar os torrents. Como se fosse o µTorrent, mas hospedado no nosso servidor.
O arquivo compose pode ficar assim:
services:
qbittorrent:
image: linuxserver/qbittorrent:latest
container_name: qbittorrent
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:8080/api/v2/app/version https://icanhazip.com
start_period: 30s
start_interval: 5s
retries: 3
ports:
- '8080:8080'
environment:
- TZ=America/Sao_Paulo
- WEBUI_PORT=8080
- PUID=1000
- PGID=1000
volumes:
- ./configs/qbittorrent:/config
- /mnt/gigachad/data/torrents:/data/torrents/
É importante colocar healthchecks em todos os containers - desde que seja possível. Como o qBitTorrent conecta à internet, o healthcheck conecta em um site simples para validar a conexão. Após iniciar o container, acesse-o por http://IP:8080.
Como estamos usando uma estrutura de arquivos específica, precisamos configurar os serviços para que usem dessa maneira. Nas configurações do qBitTorrent (Tools -> Options -> Downloads) altere Default Save Path para nosso diretório de torrents:
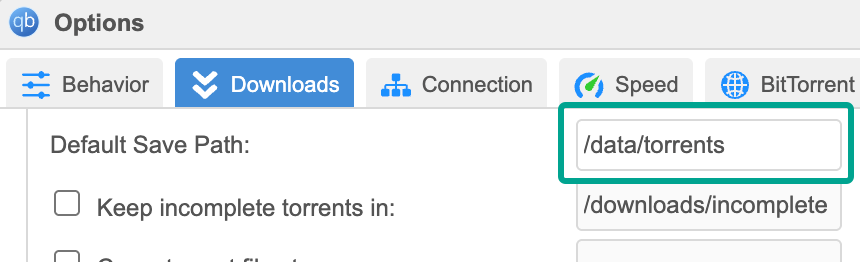
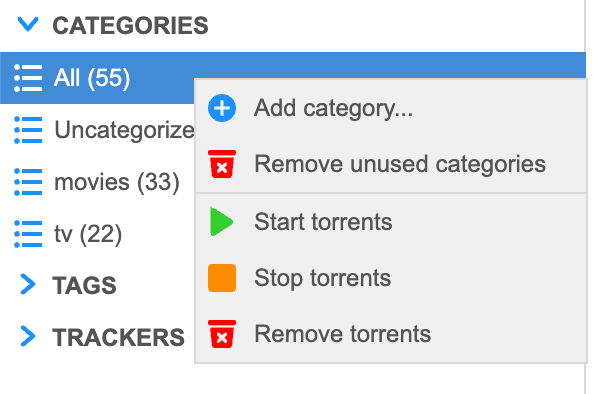
Mas como vamos separar por pastas (tv/movies)? Vamos separar por categorias. Na barra lateral da página principal, tem um menu expandível Categories, clique com o botão direito para criar. Aqui, crie duas categorias, uma para tv e outra para filmes. Para cada uma, coloque tv/tv e movies/movies:
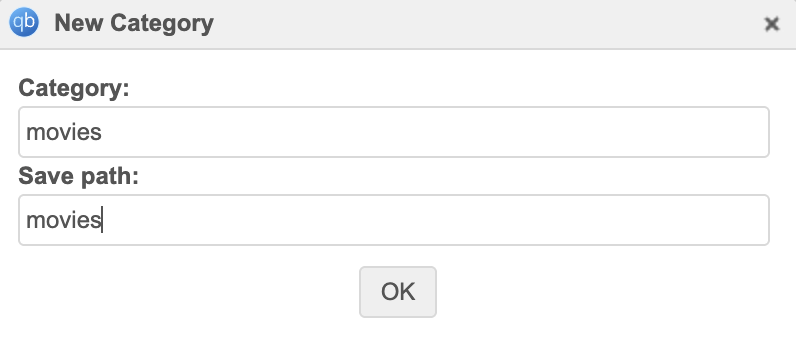
Dessa forma, filmes serão baixados em /data/torrents/movies e séries em /data/torrents/tv.
Mas e como ele irá saber o que é filme e o que é série? Iremos configurar isso no Radarr e Sonarr.
Para que essa separação entre categorias funcione, é necessário ativar o modo automático de gerenciamento. Se não ativar (por padrão vem no modo manual), filmes e séries não irão para as pastas corretas, e sim, apenas para /data/torrents/. Troque para automático no menu de acordo com a foto abaixo.
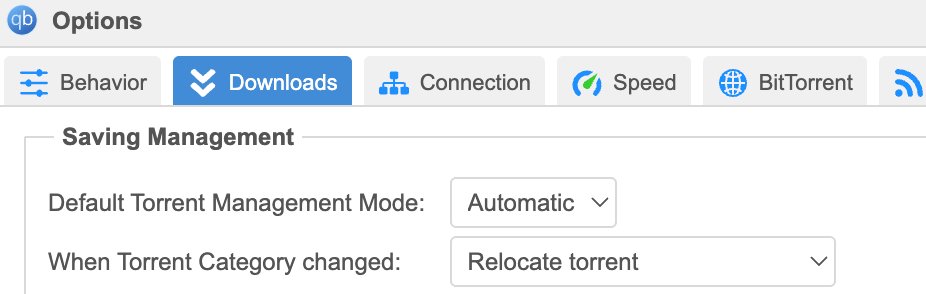
Mais informações sobre os caminhos no qBitTorrent no TRaSH Guides (vejam a imagem do link).
Flare-bypasser
Para procurar torrents, o Prowlarr (próximo a ser comentado) pesquisa em indexadores de torrents, que são os sites que você acessa para buscar algo, como TPB, RarBG, etc. Porém, alguns desses tem a proteção de DDOS da Cloudflare, que dificulta o acesso para não humanos ao colocar um captcha antes do site. Isso acontece com o 1337x, por exemplo.
Felizmente, há como contornar isso com serviços que resolvem esse captcha automático. O problema é que a Cloudflare está monitorando constantemente esses programas para bloqueá-los. Isso aconteceu com o flaresolverr, que era o mais famoso com esse propósito, porém após uma atualização da Cloudflare ele passou a não funcionar.
Após isso, optei por usar o flare-bypasser, uma alternativa direta ao flaresolverr que funciona da mesma forma. A vantagem disso é que serviços que suportam o flaresolverr (prowlar, por exemplo), também vão suportar esse, basta apontar para o container.
Adicione isso no docker-compose.yaml:
flare-bypasser:
image: ghcr.io/yoori/flare-bypasser:latest
container_name: flare-bypasser
restart: on-failure:3
environment:
UNUSED: "false"
DEBUG: "false"
VERBOSE: "false"
SAVE_CHALLENGE_SCREENSHOTS: "false"
Este é um serviço bem simples, não precisa configurar nem nada, basta deixar rodando.
Pesquisando um pouco mais, encontrei o Byparr. Provavelmente irá funcionar da mesma forma, mas como achei depois não há motivos para trocar. Escolha o que preferir.
Prowlarr
Prowlarr é um agregador de indexadores de torrents. O que este serviço faz é centralizá-los e oferecer um modo de interagir com todos os indexers em um só lugar para que outros serviços, como Radarr e Sonarr, possam buscar torrents.
Para subi-lo com docker, adicione isto no seu docker-compose.yaml:
prowlarr:
image: linuxserver/prowlarr:latest
container_name: prowlarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:9696/ping
start_period: 45s
start_interval: 5s
retries: 3
depends_on:
- flaresolverr
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- ./configs/prowlarr:/config
Adicione os indexers que preferir, o prowlarr suporta vários, desde os mais famosos e animes até os privados.
Alguns indexers irão precisar do flare-bypasser, como o 1337x. Para adicionar, vá em Settings -> Indexers -> Indexers Proxies e adicione um com o tipo FlareSolverr. Como disse anteriormente, o bypasser funciona da mesma forma que o flaresolverr, então irá funcionar. Ficará assim:
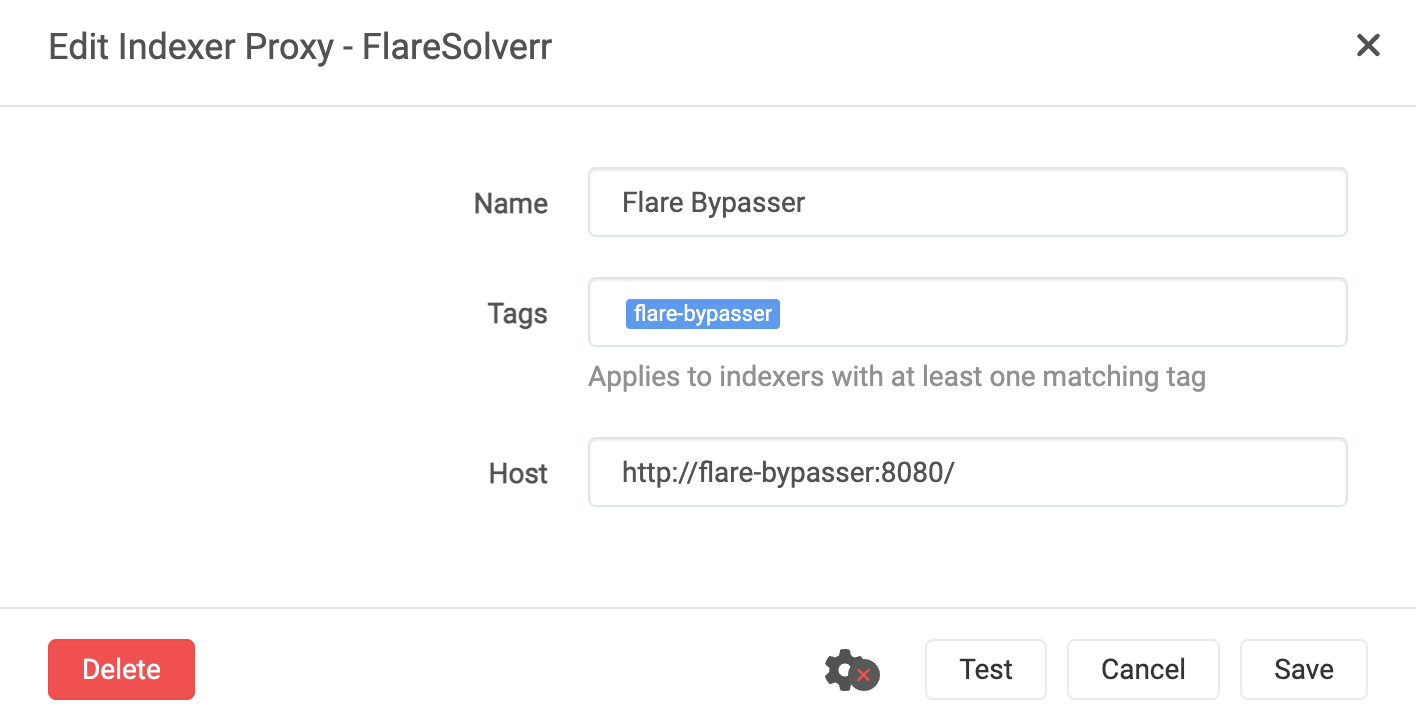
Para todos os indexers que você adicionar que esteja atrás da Cloudflare (estará escrito na hora que for adicionar), adicione a tag flare-bypasser que o prowlarr conseguirá buscar.
Radarr
Este é um dos serviços mais importantes desta stack. O Radarr é o gerenciador de, exclusivamente, filmes. Ele é o responsável por escolher um torrent de boa qualidade, e, caso encontre um que não te agrade, é possível trocar a escolha.
O Radarr também possui uma funcionalidade de pontos/ranking para cada torrent que encontra, para cada característica do torrent (codec, container, idioma, etc.) ele atribui uma pontuação. A ideia é que ele apenas faça o download dos torrents que atinjam uma pontuação mínima, assim é filtrado torrents de baixa qualidade. Essa parte é mais complicada e fica para um outro post.
Adicione-o no seu docker-compose.yaml:
radarr:
image: linuxserver/radarr:latest
container_name: radarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:7878/ping
start_period: 45s
start_interval: 5s
retries: 3
depends_on:
- qbittorrent
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- ./configs/radarr:/config
- /mnt/gigachad/data:/data
Se atente aos volumes. Neste app temos que configurar algumas coisas.
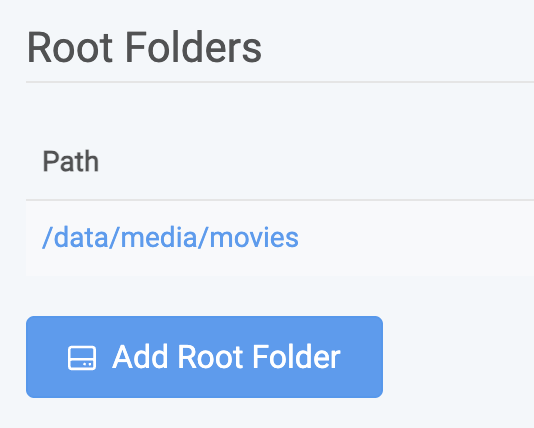
Primeiro configure o diretório de download dos filmes. Vá em Settings -> Media Management -> Add Root Folder e selecione a pasta /data/media/movies do container (que está mapeada para seu HD/SSD):
Depois, vá em Download Clients e adicione o serviço qBitTorrent. Abaixo da senha, coloque movies como categoria:
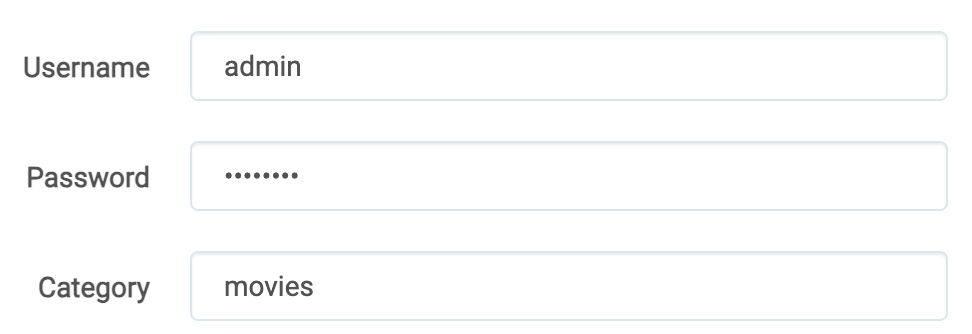 É assim que tudo fica separado em cada pasta corretamente, tanto pela pasta raíz quanto pelas categorias.
É assim que tudo fica separado em cada pasta corretamente, tanto pela pasta raíz quanto pelas categorias.
Também é necessário configurá-lo para integrar com o Prowlarr. Isso é feito no próprio Prowlarr. Abra-o e vá em Settings -> Apps e adicione a URL do Radarr:
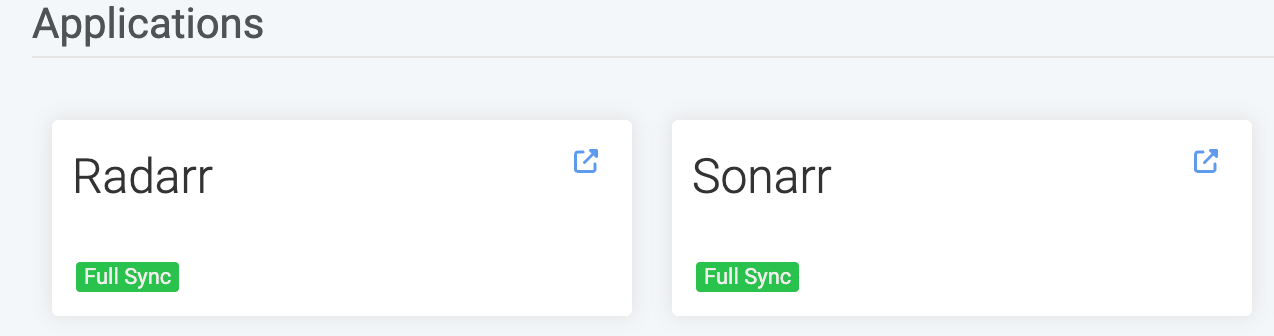
No geral, isso é o necessário para que fique funcional. Mas há várias outras configurações que valem a pena dar uma olhada, como Profiles (sistema de pontuação que mencionei), nomenclatura dos filmes (para conter informações importantes da mídia, como codecs), entre outros. Leiam a documentação.
Sonarr
Sonarr é praticamente uma cópia do Radarr, mas para séries. Faça tudo o que fez no passo anterior, mas alterando a pasta raíz para /data/media/tv e colocando tv como categoria no Download Client qBitTorrent.
Adicione no docker-compose.yaml:
sonarr:
image: linuxserver/sonarr:latest
container_name: sonarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:8989/ping
start_period: 45s
start_interval: 5s
retries: 3
depends_on:
- qbittorrent
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- ./configs/sonarr:/config
- /mnt/gigachad/data:/data
Jellyfin
Finalmente o serviço principal de toda a stack. Se você estiver lendo provavelmente já conhece o Jellyfin. Particularmente, gosto mais da UI/UX do Plex, passa um ar de um produto mais profissional e maduro, diferente do Jellyfin, que tem cada que foi criado por um desenvolvedor backend. Mas está fora de questão usar Plex devido suas últimas posições no mercado.
Jellyfin funciona independentemente, ou seja, os serviços anteriores são apenas integrações que funcionam muito bem com ele. É possível usá-lo sozinho somente buscando de uma pasta com vários filmes, por exemplo. Por isso, configurá-lo para deixar usável será mais fácil.
Adicione ao docker-compose.yaml:
jellyfin:
image: linuxserver/jellyfin:latest
container_name: jellyfin
restart: on-failure:3
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- ./configs/jellyfin/:/config
- /mnt/gigachad/data/media:/data/media
Vá em Dashboard -> Libraries -> Add Media Library. Adicione duas bibliotecas, a de filmes e séries, e configure como desejar:
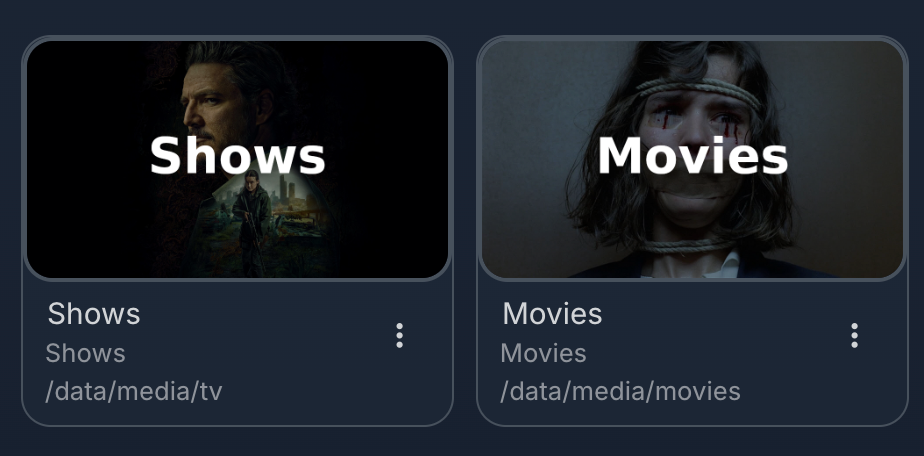
Vale a pena dar uma olhada nos plugins e nas configurações em geral pra adaptar mais ao seu uso e hardware (se houver suporte a transcoding principalmente). Minhas recomendações de plugins: Intro Skipper, OpenSubtitles, Playback Reporting, Reports, Streamyfin, Subtitle Extract.
Jellyseerr
Jellyseerr é muito útil, principalmente se mais pessoas usam seu Jellyfin. Por ele integrar com o radarr/sonarr, é possível solicitar mídias, sem precisar que você (administrador) vá manualmente no radarr e baixe por lá. Além de que os usuários podem ter logins e eles mesmos podem pedir para baixar o filme/série, e você pode escolher aceitar ou recusar.
Adicione em seu docker-compose.yaml:
jellyseerr:
image: ghcr.io/fallenbagel/jellyseerr:latest
container_name: jellyseerr
restart: on-failure:3
healthcheck:
test: "wget http://127.0.0.1:5055/api/v1/status -qO /dev/null"
interval: 30s
retries: 10
environment:
- TZ=America/Sao_Paulo
volumes:
- ./configs/jellyseerr/:/app/config
A principal configuração será a integração com o Radarr/Sonarr. Vá em Settings -> Services e adicione a URL de ambos. Usando http://radarr:7878, ele irá usar a rede do docker. Atente-se em selecionar a opção Default Server:
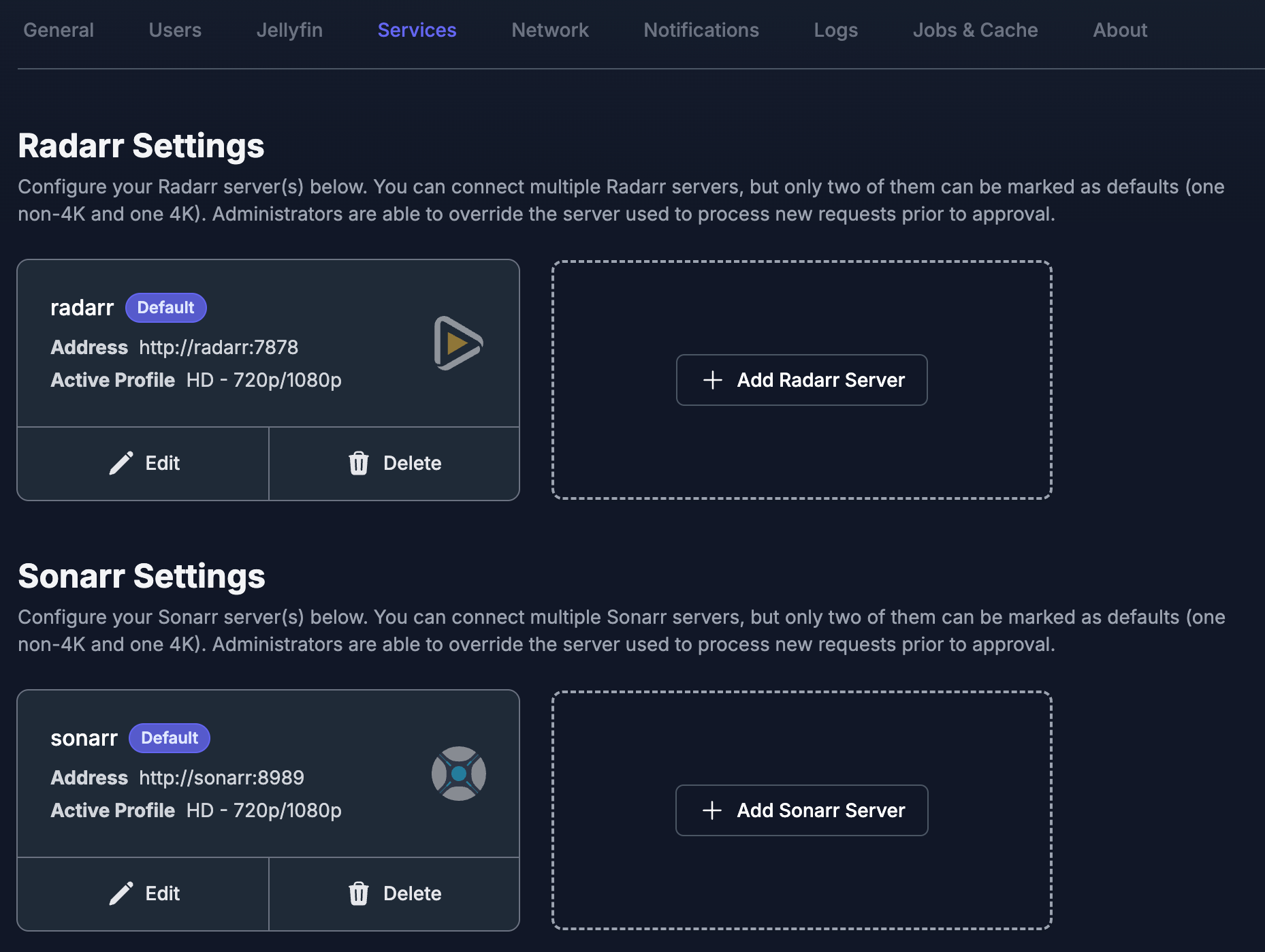
O bom do Jellyseerr é que é possível configurar notificações. Aconteceu mais de uma vez de um usuário solicitar algum filme e eu não vi. Agora, assim que alguma solicitação é feita eu sei na hora.
Bazarr
Baixar legendas sempre foi a parte chata de baixar filmes. Tem que achar uma que esteja bem sincronizada com o filme que baixou. Além disso, devido a grande maioria dos torrents serem em inglês, eles não vem com legendas em português, então tenho que ir atrás das legendas.
Apesar de ser possível baixar legendas, ainda que manualmente, com o plugin do Open Subtitles no Jellyfin, o bazarr é uma mão na roda porque ele faz esse serviço automaticamente. Ao ver que uma nova mídia foi adicionada, ele já busca legendas no idioma escolhido em diversos sites de legendas e já renomeia o arquivo pra funcionar na hora de assistir.
Adicione no seu docker-compose.yaml:
bazarr:
image: linuxserver/bazarr:latest
container_name: bazarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:6767/
start_period: 60s
start_interval: 5s
retries: 3
ports:
- 6767:6767
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- /mnt/gigachad/data/media:/data/media
- ./configs/bazarr:/config
Aqui, algumas coisas precisam ser configuradas. Vá em Settings -> Radarr/Sonarr e configure com o endereço do seu Radarr e Sonarr. É assim que ele descobre novas mídias assim que ficam disponíveis.
Vá na seção de Providers e configure todos os sites de legendas que você geralmente usa. Pra mim, estes já bastam:
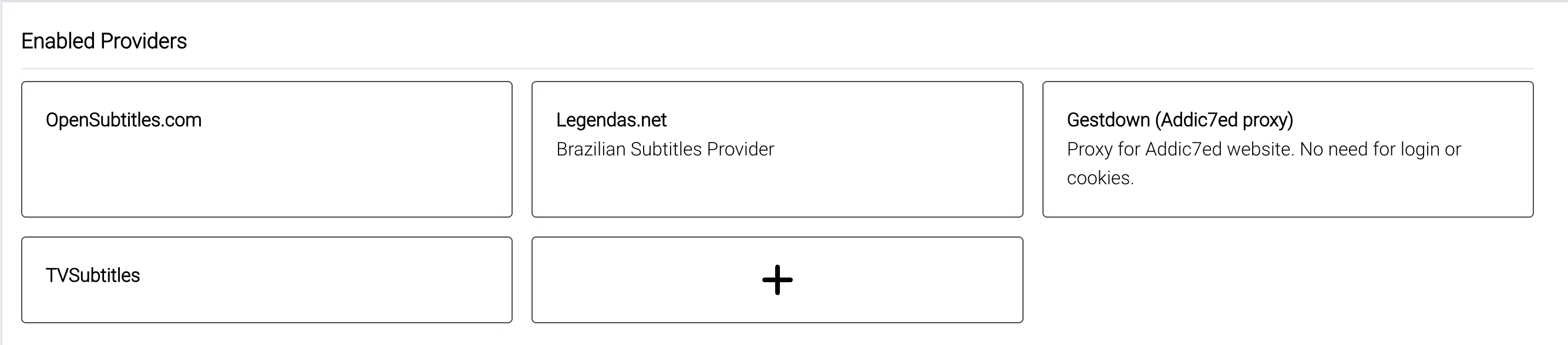
Outra parte importante é selecionar quais idiomas você deseja que baixe automataticamente, isso é feito na aba de Settings -> Languages. Nesta aba, é necessário configurar três partes: escolher os idiomas, criar um perfil de idioma e, no final da página, selecioná-los para que sejam adicionados por padrão assim que uma mídia é adicionada ao bazarr.
Com essas configurações o bazarr já irá baixar as legendas sozinho no idioma escolhido. Mas ainda não é certeiro, várias vezes já tive que mandar procurar de novo porque baixou alguma desincronizada. Mas na maioria das vezes ele acerta, o que é bom. O bazarr tem uma feature de sincronizar a legenda com o áudio, mas na minha experiência isso nunca funcionou direito.
Conclusão
Com estes serviços, já dá pra ter uma stack completa e bem automatizada. Sempre que quero assistir um novo filme, vou no meu Jellyseer, faço a request, e só. Em questão de minutos (a depender da quantidade de seeders e tamanho do filme), o filme já está pronto para assistir e já com legendas. Compartilho com mais 3 pessoas e também é o mesmo processo com eles; caso for alguém próximo, você pode configurar para aprovar o que solicitarem automaticamente.
O principal problema aqui é a parte de escolha dos torrents, que é contornada com o sistema de pontuação, e as legendas, que às vezes requer intervenção manual.
Há muito o que melhorar, no futuro faço outro post só de melhorias.
Deixarei o arquivo docker-compose.yaml completo caso queiram usá-lo.
services:
qbittorrent:
image: linuxserver/qbittorrent:latest
container_name: qbittorrent
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:8080/api/v2/app/version https://icanhazip.com
start_period: 30s
start_interval: 5s
retries: 3
ports:
- '8080:8080'
environment:
- TZ=America/Sao_Paulo
- WEBUI_PORT=8080
- PUID=1000
- PGID=1000
volumes:
- ./configs/qbittorrent:/config
- /mnt/gigachad/data/torrents:/data/torrents/
radarr:
image: linuxserver/radarr:latest
container_name: radarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:7878/ping
start_period: 45s
start_interval: 5s
retries: 3
depends_on:
- qbittorrent
ports:
- '7878:7878'
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- ./configs/radarr:/config
- /mnt/gigachad/data:/data
sonarr:
image: linuxserver/sonarr:latest
container_name: sonarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:8989/ping
start_period: 45s
start_interval: 5s
retries: 3
depends_on:
- qbittorrent
ports:
- '8989:8989'
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- ./configs/sonarr:/config
- /mnt/gigachad/data:/data
bazarr:
image: linuxserver/bazarr:latest
container_name: bazarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:6767/
start_period: 60s
start_interval: 5s
retries: 3
ports:
- '6767:6767'
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
volumes:
- /mnt/gigachad/data/media:/data/media
- ./configs/bazarr:/config
flare-bypasser:
image: ghcr.io/yoori/flare-bypasser:latest
container_name: flare-bypasser
restart: on-failure:3
environment:
UNUSED: "false"
DEBUG: "false"
VERBOSE: "false"
SAVE_CHALLENGE_SCREENSHOTS: "false"
prowlarr:
image: linuxserver/prowlarr:latest
container_name: prowlarr
restart: on-failure:3
healthcheck:
test: curl -fsS http://127.0.0.1:9696/ping
start_period: 45s
start_interval: 5s
retries: 3
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
ports:
- '8191:8191'
volumes:
- ./configs/prowlarr:/config
jellyfin:
image: linuxserver/jellyfin:latest
container_name: jellyfin
restart: on-failure:3
environment:
- TZ=America/Sao_Paulo
- PUID=1000
- PGID=1000
ports:
- '8096:8096'
volumes:
- ./configs/jellyfin/:/config
- /mnt/gigachad/data/media:/data/media
jellyseerr:
image: ghcr.io/fallenbagel/jellyseerr:latest
container_name: jellyseerr
restart: on-failure:3
healthcheck:
test: "wget http://127.0.0.1:5055/api/v1/status -qO /dev/null"
interval: 30s
retries: 10
environment:
- TZ=America/Sao_Paulo
ports:
- '5055:5055'
volumes:
- ./configs/jellyseerr/:/app/config